انجام پروژه هایه کراس keras
انجام پروژه هایه متن کاوی یادگیری عمیق با کراس keras
انجام پروژه هایه متن کاوی با کراس keras
فریم ورک کراس keras چیست ?
فریم ورک کراس در سال 2015 توسط فرانچیوس چولت معرفی شد .در واقع کراس شبیه فریم ورک هایه یادگیری عمیق مثله cntk -تنسرفلو- می باشد که از آن برای ساخت شبکه هایه عصبی استفاده می شود .کراس در واقع پلت فرم سطح بالا می باشد پیچیدگی زیادی را حذف می کند .از خصوصیت هایه دیگر فریم ورک کراس محدود به شبکه عصبی نمی شود همانند تنسرفلو وcntk برای سایر محاسبات نیز استفاده می شود .
در هر شرایط استفاده از کراس بهترین مدل استفاده در پیاده سازیها نیست و باید دانست چه زمانی از آن استفاده کنیم.
مراحل انجام پروژه پردازش متن در کراس
برای انجام پروژه پردازش متن با استفاده از کراس (Keras)، میتوانید مراحل زیر را دنبال کنید:
جمعآوری داده: ابتدا باید دادههای مورد نیاز برای پروژه خود را جمعآوری کنید. ممکن است این شامل مجموعهای از متنها، مثلاً مقالات، نظرات مشتریان، توییتها و غیره باشد.
پیشپردازش داده: در این مرحله، باید دادههای جمعآوری شده را پیشپردازش کنید. به عنوان مثال، ممکن است نیاز به تمیزکاری متن (از برداشتن نقطه ویرگول، حذف کلمات اضافی و غیره)، تبدیل متن به بردارهای عددی با استفاده از روشهایی مانند واقعیسازی معنایی و یا تفکیک برچسبها (Label Encoding) داشته باشید.
تقسیم داده: برای آموزش مدل، باید دادههای خود را به دو قسمت آموزشی و ارزیابی (و در صورت نیاز، قسمت تست) تقسیم کنید. این کار هدفش ارزیابی عملکرد مدل در دادههای جدید است که قبلاً دیده نشدهاند.
طراحی معماری مدل: حالا نوبت به طراحی مدل خود با استفاده از کراس میرسد. معمولاً این شامل تعریف لایههای مختلف شبکه عصبی، مشخص کردن تعداد واحدها در هر لایه، انتخاب تابع فعالسازی و غیره است. معمولاً از لایههایی مانند Embedding، LSTM یا Convolutional Layers و Dense Layers برای پیادهسازی مدلهای پردازش متن استفاده میشود.
آموزش مدل: در این مرحله، مدل خود را روی دادههای آموزشی آموزش میدهید. برای این کار، باید یک تابع هزینه (loss function) و روش بهینه سازی را مشخص کنید. سپس با استفاده از تابع fit() در کراس، مدل را آموزش داده و پارامترهای آن را بهبود دهید.
ارزیابی مدل: پس از آموزش، باید عملکرد مدل را بر روی دادههای ارزیابی ارزیابی کنید. این شامل محاسبه معیارهایی مانند دقت (accuracy)، فراخوانی (recall) و دقت پیشبینی (precision) است.
تغییرات و بهینهسازی: ممکن است نیاز به تغییر معماری مدل، تغییر پارامترها، تبدیل الگوریتمها و غیره باشد. در این مرحله، میتوانید تغییرات لازم را اعمال کنید و تلاش کنید عملکرد مدل خود را بهبود ببخشید.
این مراحل عمومی برای انجام یک پروژه پردازش متن با استفاده از کراس هستند. البته، وابسته به نوع پروژه و مسئله مورد نظر شما، مراحل و تنظیمات ممکن است متفاوت باشند.
مراحل جمع اوری داده پردازش متن برای کراس
مراحل جمعآوری و پردازش داده برای پروژه پردازش متن با استفاده از کراس عبارتند از:
جمعآوری داده: برای شروع، باید دادههای متنی مورد نیاز خود را جمعآوری کنید. میتوانید از منابع مختلف مانند وبسایتها، پایگاهدادهها، APIها یا فایلهای متنی استفاده کنید.
تمیزکاری داده: بعد از جمعآوری دادهها، لازم است آنها را تمیزکنید. این شامل حذف هرگونه نویز، علائم نگارشی غیرضروری، کلمات اضافی، فضای خالی، علائم نگارشی و سایر عناصر غیرمورد نیاز است. همچنین ممکن است بخواهید بر روی دادهها عملیات نرمالسازی یا واقعیسازی اعمال کنید.
تقسیم داده: بعد از تمیزکاری دادهها، آنها را به سه قسمت تقسیم میکنیم، یعنی دادههای آموزشی، ارزیابی و آزمون. دادههای آموزشی برای آموزش مدل استفاده میشوند، دادههای ارزیابی برای ارزیابی عملکرد مدل در هنگام آموزش استفاده میشوند و دادههای آزمون برای ارزیابی نهایی مدل پس از آموزش استفاده میشوند.
واکشی داده: با استفاده از کراس، باید دادهها را بارگیری کنید و آنها را به فرمت مناسب برای استفاده در مدل ورودی کنید. این شامل تبدیل متن به بردارهای عددی با استفاده از توکنسازی (tokenization)، جانشینی کلمات با شناسه (word embedding) و سایر روشهای مشابه است.
طراحی مدل: در این مرحله، باید معماری مدل خود را با استفاده از کراس طراحی کنید. این شامل تعریف و پیکربندی لایههای شبکه عصبی مانند LSTM، Convolutional Layers و Dense Layers است. همچنین میتوانید از تکنیکهایی مانند Dropout و Batch Normalization برای بهبود عملکرد مدل استفاده کنید.
آموزش مدل: در این مرحله، مدل خود را با استفاده از دادههای آموزشی آموزش میدهید. برای این کار، یک تابع هزینه مناسب (مانند cross-entropy) و روش بهینهسازی (مانند Adam) را مشخص میکنید. سپس با استفاده از تابع fit() در کراس، مدل را آموزش داده و پارامترهای آن را بهبود دهید.
ارزیابی مدل: پس از آموزش، عملکرد مدل را روی دادههای ارزیابی ارزیابی کنید. میتوانید از معیارهایی نظیر دقت (accuracy)، دقت پیشبینی (precision) و بازخوانی (recall) استفاده کنید تا عملکرد مدل را ارزیابی کنید.
بهبود مدل: بررسی عملکرد مدل و در صورت لزوم، تغییرات در معماری مدل، هیپرپارامترها و روشهای آموزش را اعمال کنید تا عملکرد مدل بهبود یابد.
همچنین، باید توجه داشت که مراحل بالا به طور کلی هستند و بسته به نوع مسئله، میتوانید تغییراتی در این مراحل ایجاد کنید.
تشکیل بردار ویژگی انجام پروژه پردازش متن کراس
در پروژههای پردازش متن با استفاده از کتابخانه کراس (Keras)، میتوانید از روشهای مختلف برای تشکیل بردار ویژگی استفاده کنید. در زیر چند روش رایج برای تشکیل بردار ویژگی در پردازش متن با استفاده از کراس را معرفی میکنم:
تبدیل متن به بردارهای عددی با استفاده از تکنیکهای واحدسازی و کدگذاری متن:
One-Hot Encoding: هر کلمه را با یک بردار صفر و یک جایگشتی از صفرها و یک در نشان میدهیم.
Word Embeddings: از مدلهای مانند Word2Vec, GloVe یا FastText استفاده کنید تا کلمات را به فضای برداری تبدیل کنید و آنها را به عنوان بردارهای ویژگی استفاده کنید.
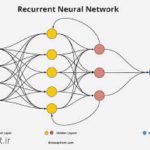
استفاده از شبکههای عصبی بازگشتی (RNN) و یا شبکههای بازگشتی درونزمانی (LSTM) برای استخراج ویژگی از توالیهای متنی، مانند جملات و سندها. در این روشها، هر کلمه به صورت ترتیبی پردازش میشود و بردار وضعیت نهان آخرین لایه شبکه میتواند به عنوان بردار ویژگی نهایی استفاده شود.
استفاده از شبکههای پیچشی (CNN) برای استخراج ویژگی از جملات و سندها. در این روش، بردار ویژگی از هر جمله با استفاده از لایههای پیچشیای استخراج میشود که الگوهای مختلف متنی را تشخیص میدهد.
استفاده از ترکیبی از شبکههای CNN و RNN برای استخراج ویژگیهای جانبی متن. در این روش، شبکههای CNN برای استخراج ویژگیهای محلی از جملات استفاده میشوند و سپس شبکه RNN برای درک و روابط طولانیمدت بین ویژگیها استفاده میشود.
در هر روش، لازم است که دادههای خروجی را با استفاده از لایههایی مانند لایههای Dropout و Dense در کراس به شبکه عصبی متصل کنید تا به صورت نهایی پیشبینی را انجام دهد. همچنین میتوانید با تغییر پارامترها و آزمایش با روشهای مختلف بهترین نتیجه را برای پروژه خود بدست آورید.
تشکیل بردار ویژگی انجام پروژه پردازش متن کراس
در پروژههای پردازش متن با استفاده از کتابخانه کراس (Keras)، میتوانید از روشهای مختلف برای تشکیل بردار ویژگی استفاده کنید. در زیر چند روش رایج برای تشکیل بردار ویژگی در پردازش متن با استفاده از کراس را معرفی میکنم:
تبدیل متن به بردارهای عددی با استفاده از تکنیکهای واحدسازی و کدگذاری متن:
One-Hot Encoding: هر کلمه را با یک بردار صفر و یک جایگشتی از صفرها و یک در نشان میدهیم.
Word Embeddings: از مدلهای مانند Word2Vec, GloVe یا FastText استفاده کنید تا کلمات را به فضای برداری تبدیل کنید و آنها را به عنوان بردارهای ویژگی استفاده کنید.
استفاده از شبکههای عصبی بازگشتی (RNN) و یا شبکههای بازگشتی درونزمانی (LSTM) برای استخراج ویژگی از توالیهای متنی، مانند جملات و سندها. در این روشها، هر کلمه به صورت ترتیبی پردازش میشود و بردار وضعیت نهان آخرین لایه شبکه میتواند به عنوان بردار ویژگی نهایی استفاده شود.
استفاده از شبکههای پیچشی (CNN) برای استخراج ویژگی از جملات و سندها. در این روش، بردار ویژگی از هر جمله با استفاده از لایههای پیچشیای استخراج میشود که الگوهای مختلف متنی را تشخیص میدهد.
استفاده از ترکیبی از شبکههای CNN و RNN برای استخراج ویژگیهای جانبی متن. در این روش، شبکههای CNN برای استخراج ویژگیهای محلی از جملات استفاده میشوند و سپس شبکه RNN برای درک و روابط طولانیمدت بین ویژگیها استفاده میشود.
در هر روش، لازم است که دادههای خروجی را با استفاده از لایههایی مانند لایههای Dropout و Dense در کراس به شبکه عصبی متصل کنید تا به صورت نهایی پیشبینی را انجام دهد. همچنین میتوانید با تغییر پارامترها و آزمایش با روشهای مختلف بهترین نتیجه را برای پروژه خود بدست آورید.
لیست کاربردهای کراس
کتابخانهی کراس (Keras) یک کتابخانه محبوب برای ساخت و آموزش شبکههای عصبی در پایتون است که بر روی TensorFlow کار میکند. به دلیل سادگی و قدرت خود، کراس در بسیاری از بخشهای یادگیری عمیق و پژوهش های تشخیص الگو، پردازش زبان طبیعی، تصویربرداری و غیره استفاده میشود.
در زیر فهرستی از کاربردهای کراس را میتوانید بیابید:
تشخیص الگو: از جمله کاربردهای مشهور کراس، تشخیص الگو و طبقهبندی مسائل مختلف است. مثلاً تشخیص چهره، تشخیص نوشتهها، تشخیص اشیاء و غیره.
پردازش زبان طبیعی: کراس برای پردازش متون طبیعی، ایجاد مدلهایی برای ترجمه ماشینی، خلاصهنویسی خودکار، تولید شرح خودکار برای تصاویر و سایر وظایف مربوط به پردازش زبان طبیعی استفاده میشود.
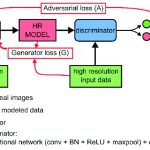
تصویربرداری: در تصویربرداری، کراس برای دستهبندی تصاویر، شناسایی اشیاء، تشخیص چهره، تولید تصویر و پردازش تصاویر پزشکی و غیره استفاده میشود.
پیشبینی و پیشگویی: با استفاده از کراس، میتوانید مدلهایی برای پیشبینی مقادیر آینده بسازید. مثلاً پیشبینی قیمت سهام، توقعات بازار، پیشبینی هوا و غیره.
یادگیری تقویتی: کراس میتواند در الگوریتمهای یادگیری تقویتی مورد استفاده قرار بگیرد. این الگوریتمها برای یادگیری عاملها در محیطهای تعاملی استفاده میشوند، مانند بازیها و رباتها.
یادگیری انتقالی: با استفاده از کراس، میتوانید مدلهای از پیش آموزشدیده را به عنوان شبکههای پایه برای حل مسائل مرتبط استفاده کنید. این روش به شما کمک میکند تا با دادههای کمتر و زمان کمتر، مدلهای قدرتمندتری بسازید.
این فقط چند نمونه از کاربردهای کراس هستند و در واقعیت، این کتابخانه در حوزههای بسیاری از یادگیری عمیق استفاده میشود و کاربردهای بیشتری نیز دارد.
تولید متن خلاقانه: کراس میتواند برای تولید متن خلاقانه و شعرها، داستانها، موسیقی و سایر اجزای خلاقیت استفاده شود.
تشخیص تقلب: با استفاده از کراس، میتوانید مدلهایی بسازید که قادر به تشخیص تقلب در محصولات و خدمات مختلف باشند. مثلاً تشخیص تقلب در تراکنشهای مالی یا تشخیص تقلب در محصولات و غیره.
توصیهگر: کراس به عنوان یک توصیهگر میتواند در وبسایتها، برنامههای موبایل و سایر سیستمها برای پیشنهاد محصولات، فیلمها، آهنگها و سایر موارد مورد استفاده قرار بگیرد.
تحلیل احساسات: با استفاده از کراس، میتوانید مدلهایی بسازید که قادر به تحلیل و پیشبینی احساسات در متون و نظرات مختلف باشند. مثلاً تحلیل احساسات کاربران دربارهی یک محصول یا نظرات در شبکههای اجتماعی.
بازیابی اطلاعات: کراس میتواند در سیستمهای بازیابی اطلاعات برای جستجوی پیشرفته و استخراج اطلاعات مورد استفاده قرار بگیرد.
تشخیص تقلید صدا: میتوانید با استفاده از کراس، مدلهایی بسازید که قادر به تشخیص تقلید صدا و تبدیل صداها به صداهای مشخص باشند. این میتواند برای تطبیق صدای تلفنی و همچنین در صنایع موسیقی و تولید صدا مورد استفاده قرار بگیرد.
خودران: کراس میتواند در توسعه خودروهای خودران و شناسایی علائم راهنما و شناسایی ترافیک استفاده شود.
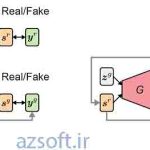
شبکه های مولد: کراس میتواند برای ساخت شبکههای مولد (Generative Models) استفاده شود. این شبکهها برای تولید تصاویر ویدئویی، تصاویر واقع گرایانه و سایر دادههای قابل تولید استفاده میشوند.
مطمئناً کاربردهای کراس از این فهرست بیشتر است و با گسترش حوزههای مورد استفاده یادگیری عمیق، کاربردهای جدیدتری نیز به وجود خواهد آمد.


پاسخ دادن