انجام پروژه های rnn ،پیاده سازی پروژه های rnn انجام پروژه های پردازش متن rnn
گروه یادگیری عمیق سایت azsoftir آماده انجام پروژه های شبکه عصبی شما با استفاده از یادگیری عمیق rnn می باشد ،با توجه سابقه چندین سایت azsoftir کیفیت وانجام پروژه دقیق شما را تضمین می کند .
برای ثبت سفارش چگونه باید اقدام کرد؟
برای ثبت سفارش می توانید از طریق ایمیل آدرس azsoftir یا شماره تماس 09367292276 اقدام کنید .
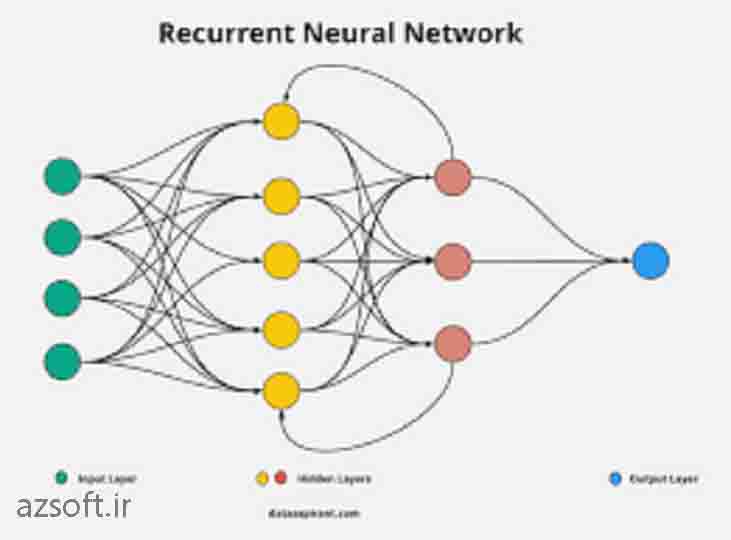
لیست سرویس هایی که در زمینه انجام پروژه های شبکه عصبی rnn قابل انجام است ؟
پیاده سازی مقالات با استفاده از شبکه عصبی rnn
انجام پروژه های پردازش متن با rnn
انجام پروژه بینایی ماشین rnn
انجام پروژه پردازش تصویرrnn
انجام پروژه های یادگیری ماشین با rnn
انجام پروژه های شبکه عصبی برگشتی
انجام پروژه rnn
انجام پروژه مهندسی پزشکی با rnn
شروع انجام پروژه شبکه های عصبی rnn چگونه خواهد بود؟
برای شروع پروژه rnn باید ابتدا نصف هزینه توافقی رو واریز کنید ،بعد از اتمام نصف دیگر را واریز می کنید تا پروژه مورد نظر شما ارسال شود .
کیفیت انجام پروژه های rnn چگونه خواهد بود ؟
با توجه سابقه سایت azsoftir در زمینه انجام پروژه های هوش مصنوعی ،کیفیت پروژه را تضمین میکند .
سایت azsoftir با سابقه چندین ساله در زمینه هوش مصنوعی وشبکه عصبی کیقیت انجام پروژه شبکه rnn را تضمین میکند .
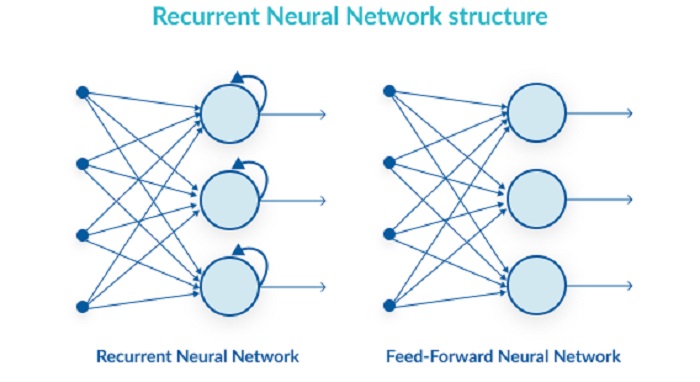
تاریخچه شبکه عصبی rnn
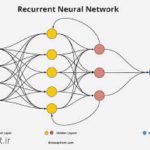
شبکههای عصبی بازگشتی (RNN) یکی از مدلهای پیشرفته در حوزه یادگیری ماشین و هوش مصنوعی هستند که برای پردازش دادههای دنبالهای مانند متن و گفتار استفاده میشوند. تاریخچه شبکههای RNN به دهه 1980 بازمیگردد و از آن زمان تاکنون توسعههای قابل توجهی داشتهاند.
آغازین
1982: اولین مفهوم شبکههای عصبی بازگشتی توسط جان هاپفیلد معرفی شد. مدل هاپفیلد، که به نام خود او نامیده شده، یک نوع شبکه عصبی بازگشتی است که برای ذخیرهسازی و بازیابی الگوها به کار میرود.
1986: دیوید روملهارت و جیمز مککللند مدل شبکههای عصبی بازگشتی را در کتاب “Parallel Distributed Processing” به طور گستردهای معرفی کردند. آنها ایده استفاده از واحدهای بازگشتی در شبکههای عصبی را برای حفظ اطلاعات از گذشته توضیح دادند.
توسعه و پیشرفت
1990: جردن نتورک (Jordan Network) و المن نتورک (Elman Network) به عنوان دو نوع از شبکههای عصبی بازگشتی ساده معرفی شدند. این مدلها قادر به حفظ حافظه کوتاه مدت بودند.
1997: Sepp Hochreiter و Jürgen Schmidhuber مدل Long Short-Term Memory (LSTM) را معرفی کردند. LSTM یک نقطه عطف در توسعه RNN بود زیرا توانایی آن در حفظ اطلاعات برای دورههای طولانیتر، مشکل محو شدن گرادیان را که در مدلهای RNN سنتی وجود داشت، به طور قابل توجهی کاهش داد.
2000s: با پیشرفت در قدرت محاسباتی و دسترسی به دادههای بزرگتر، شبکههای عصبی بازگشتی در کاربردهای مختلفی مانند ترجمه ماشینی، تولید متن، و تشخیص گفتار به کار رفتند.
اخیر
2014-2020: معرفی شبکههای عصبی بازگشتی متغیر (GRU) که یک سادهسازی از LSTM است اما با کارایی مشابه. همچنین، توسعه در مدلهای توجه (Attention models) که باعث بهبود قابل توجهی در کارایی مدلهای مبتنی بر RNN شد.
به امروز: شبکههای عصبی بازگشتی همچنان در حال توسعه هستند و در کنار مدلهای جدیدتر مانند Transformer، که برای پردازش دادههای دنبالهای استفاده میشوند، قرار دارند.
شبکههای RNN به دلیل قابلیتهای منحصر به فرد خود در پردازش سریهای زمانی و دادههای دنبالهای، از اهمیت بالایی برخوردار هستند و پیشبینی میشود که توسعه و بهبود آنها همچنان ادامه یابد.
چالشها و راهحلها
در طول توسعه شبکههای عصبی بازگشتی (RNN)، محققان با چالشهای مختلفی مواجه شدهاند که به نوآوریها و پیشرفتهای قابل توجهی منجر شده است.
مشکل محو شدن و انفجار گرادیان
یکی از بزرگترین چالشها در کار با RNNها، مشکل محو شدن و انفجار گرادیان است. در طول آموزش، گرادیانهایی که از طریق شبکه بازگشت میکنند میتوانند به سرعت کاهش یابند (محو شوند) یا افزایش یابند (انفجار کنند)، که هر دو میتوانند مانع از آموزش موثر شبکه شوند. LSTM و GRU دو راهحل برای مقابله با مشکل محو شدن گرادیان هستند که با ارائه مکانیزمهای فراموشی و بهروزرسانی، به حفظ اطلاعات برای دورههای زمانی طولانیتر کمک میکنند.
نیاز به مدلهای پیچیدهتر
با افزایش پیچیدگی واقعیتهایی که میخواهیم با استفاده از RNN مدل کنیم، نیاز به مدلهای پیچیدهتر و قدرتمندتر نیز افزایش یافته است. مدلهایی مانند Transformer، که از مکانیزم توجه برای بهبود کارایی در پردازش دنبالههای طولانی استفاده میکنند، نمونههایی از این پیشرفتها هستند. این مدلها توانستهاند در بسیاری از کاربردها، از جمله ترجمه ماشینی، تولید متن، و پردازش زبان طبیعی، عملکرد بهتری نسبت به RNNهای سنتی ارائه دهند.
بهینهسازی و مقیاسپذیری
با افزایش حجم دادهها و پیچیدگی مدلها، بهینهسازی و مقیاسپذیری آموزش شبکههای عصبی بازگشتی به یک چالش مهم تبدیل شده است. استفاده از تکنیکهای مانند آموزش موازی و شبکههای توزیعشده، به همراه بهینهسازیهای الگوریتمی، برخی از روشهایی هستند که برای مقابله با این چالشها به کار رفتهاند.
آینده RNNها
با وجود پیشرفتهای قابل توجه در مدلهای جدیدتر مانند Transformer، RNNها همچنان یک ابزار مهم در پردازش دادههای دنبالهای هستند. تحقیقات جاری در بهبود معماریهای RNN، از جمله توسعه واریانتهای جدید و بهینهسازی مدلهای موجود، ادامه دارد. همچنین، ترکیب RNNها با دیگر مدلهای یادگیری عمیق، مانند شبکههای توجه و شبکههای عصبی کانولوشنی (CNN)، راههای جدیدی برای حل مسائل پیچیدهتر ارائه میدهد.
در نهایت، با پیشرفتهای مستمر در فناوریهای محاسباتی و الگوریتمهای یادگیری ماشین، میتوان انتظار داشت که شبکههای عصبی بازگشتی به همراه سایر مدلهای یادگیری عمیق، در آینده نزدیک نقش هر چه بیشتری در پیشبرد حوزههای مختلف علمی و صنعتی ایفا کنند.
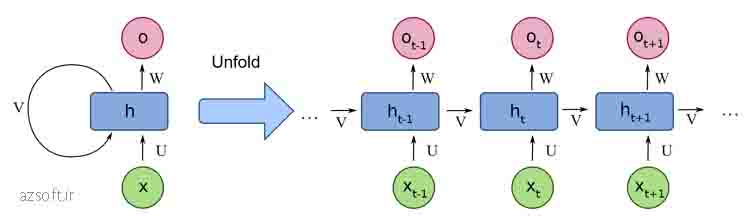
کاربرد شبکه عصبی rnn
شبکههای عصبی بازگشتی (RNN) به دلیل قابلیت خود در پردازش دادههای دنبالهای و حفظ اطلاعات از گذشته، در بسیاری از کاربردهای مختلف مورد استفاده قرار میگیرند. در اینجا به برخی از مهمترین کاربردهای RNN اشاره میکنیم:
پردازش زبان طبیعی (NLP)
ترجمه ماشینی: RNNها میتوانند برای ترجمه متون از یک زبان به زبان دیگر استفاده شوند، به طوری که جملات ورودی را درک کرده و معادلهای دقیق آنها را به زبان هدف تولید کنند.
تولید متن: از RNNها میتوان برای تولید متن خودکار استفاده کرد، مثلاً تولید محتوا، خبرنامهها، یا حتی داستاننویسی خلاق.
تشخیص گفتار: تبدیل گفتار به متن نیز یکی دیگر از کاربردهای RNN است که در سیستمهای دستیار صوتی و ترجمه گفتار زنده کاربرد دارد.
تحلیل احساسات
تشخیص نظرات: RNNها میتوانند برای تحلیل نظرات کاربران در شبکههای اجتماعی، بررسیهای محصولات و خدمات استفاده شوند تا تعیین کنند که یک نظر مثبت، منفی یا خنثی است.
تشخیص الگو در دادههای زمانی
پیشبینی سری زمانی: در اقتصاد، مالی، هواشناسی و بسیاری زمینههای دیگر، RNNها میتوانند برای پیشبینی روندهای آینده بر اساس دادههای گذشته استفاده شوند.
تجزیه و تحلیل بازار سهام: تشخیص الگوهای بازار و پیشبینی قیمتهای آینده سهام یکی دیگر از کاربردهای مهم RNN است.
پردازش تصویر و ویدئو
تشخیص فعالیت در ویدئوها: RNNها میتوانند برای تشخیص و تفسیر فعالیتهای انجام شده در دنبالههای ویدئویی استفاده شوند.
تولید توضیحات برای تصاویر: با ترکیب CNN و RNN، میتوان توضیحاتی را برای تصاویر تولید کرد که جزئیات موجود در تصویر را به طور خودکار شرح دهد.
موسیقی و هنر
تولید موسیقی: RNNها میتوانند برای تولید قطعات موسیقی جدید با تقلید از سبکهای موسیقایی خاص استفاده شوند.
تولید هنر خلاق: از RNNها میتوان در تولید آثار هنری خلاق، مانند نقاشی و شعر، استفاده کرد.
اینها تنها بخشی از کاربردهای متنوع و گستردهای هستند که RNNها در آنها مورد استفاده قرار میگیرند. با پیشرفت تکنولوژی و تحقیقات بیشتر در حوزه یادگیری عمیق، انتظار میرود که کاربردهای جدید و هیجانانگیزتری برای RNNها کشف شود.
لیست توابع مهم انجام پروژه rnn پایتون
برای انجام پروژههای مرتبط با شبکههای عصبی بازگشتی (RNN) در پایتون، معمولاً از کتابخانههایی مانند TensorFlow یا PyTorch استفاده میشود. این کتابخانهها دارای توابع و کلاسهای متعددی هستند که برای ساخت، آموزش و آزمایش شبکههای RNN ضروری میباشند. در ادامه، لیستی از توابع و کلاسهای مهم در TensorFlow و PyTorch ارائه شده است:
TensorFlow
tf.keras.layers.SimpleRNN: یک لایه RNN ساده با تعداد قابل تنظیم نورون.
tf.keras.layers.LSTM: برای ایجاد لایههای Long Short-Term Memory (LSTM), که یک نوع خاص از RNN است.
tf.keras.layers.GRU: برای ایجاد لایههای Gated Recurrent Unit (GRU), که یک نوع دیگر از RNN است.
tf.keras.Model: برای ساخت مدلهای پیچیدهتر که میتواند شامل چندین لایه RNN و سایر لایهها باشد.
model.compile(): برای تنظیم تابع خطا، بهینهساز و معیارهای ارزیابی.
model.fit(): برای آموزش مدل بر روی دادهها.
model.evaluate(): برای ارزیابی عملکرد مدل بر روی دادههای تست.
model.predict(): برای پیشبینی خروجیها با استفاده از مدل آموزش دیده.
PyTorch
torch.nn.RNN: برای ایجاد یک لایه RNN ساده.
torch.nn.LSTM: برای ایجاد لایههای LSTM.
torch.nn.GRU: برای ایجاد لایههای GRU.
torch.nn.Module: کلاس اصلی برای ساخت مدلهای شبکه عصبی در PyTorch.
torch.optim: ماژولی که شامل بهینهسازهای مختلف مانند Adam, SGD و غیره است.
loss.backward(): برای محاسبه گرادیانها در فرآیند backpropagation.
optimizer.step(): برای بهروزرسانی وزنها بر اساس گرادیانهای محاسبه شده.
torch.utils.data.DataLoader: برای بارگذاری و دستکاری دادهها در بچها به منظور آموزش موثرتر.
این توابع و کلاسها پایه و اساس ایجاد، آموزش و استفاده از شبکههای RNN در پروژههای مرتبط با یادگیری عمیق به شمار میروند.
لیست توابع مهم انجام پروژه rnn متلب
برای انجام پروژههای مرتبط با شبکههای عصبی بازگشتی (RNN) در متلب (MATLAB)، میتوانید از جعبه ابزار Deep Learning Toolbox استفاده کنید. این جعبه ابزار امکانات و توابع متعددی را برای ساخت، آموزش، و ارزیابی شبکههای عصبی عمیق از جمله RNNها فراهم میکند. در ادامه، لیستی از توابع و قابلیتهای کلیدی ارائه شده است که برای کار با RNNها در متلب مفید هستند:
ساخت شبکه
sequenceInputLayer: ایجاد یک لایه ورودی برای دنبالهها.
lstmLayer: اضافه کردن یک لایه LSTM به شبکه.
gruLayer: اضافه کردن یک لایه GRU به شبکه.
bilstmLayer: اضافه کردن یک لایه LSTM دوجهته به شبکه.
fullyConnectedLayer: ایجاد یک لایه کاملا متصل.
softmaxLayer: ایجاد یک لایه softmax برای طبقهبندی.
classificationLayer: ایجاد یک لایه طبقهبندی.
آموزش و ارزیابی
trainingOptions: تنظیم گزینههای آموزش مانند نرخ یادگیری، تعداد دورهها، و الگوریتم بهینهسازی.
trainNetwork: آموزش شبکه با دادههای آموزشی و تنظیمات مشخص شده.
predict: پیشبینی خروجیها با استفاده از شبکه آموزش دیده.
کار با دادهها
sequenceDatastore: ایجاد یک datastore برای کار با دنبالههای دادهای.
combine: ترکیب دو یا چند datastore.
miniBatchSize: تنظیم اندازه mini-batch برای آموزش.
سایر توابع مفید
analyzeNetwork: نمایش یک دیاگرام تعاملی از ساختار شبکه.
exportONNXNetwork: صادر کردن شبکه به فرمت ONNX برای استفاده در سایر پلتفرمها.
این لیست توابع و قابلیتها، شما را قادر میسازد تا شبکههای RNN را برای انواع مختلفی از کاربردها، از جمله پردازش زبان طبیعی و تجزیه و تحلیل سری زمانی، در متلب پیادهسازی و آموزش دهید.
توضیح پارامترهای شبکه عصبی rnn در پایتون
شبکههای عصبی بازگشتی (RNN) برای پردازش دنبالههای دادهای مانند متن یا سریهای زمانی طراحی شدهاند. در پایتون، کتابخانههایی مانند TensorFlow و PyTorch امکان ساخت و آموزش این نوع شبکهها را فراهم میکنند. در اینجا به توضیح پارامترهای اصلی و مهمی که هنگام تعریف یک RNN در این کتابخانهها باید در نظر گرفت، میپردازیم.
TensorFlow (با استفاده از Keras)
tf.keras.layers.SimpleRNN
units: تعداد نورونها در لایه RNN، که نشاندهنده ابعاد فضای خروجی است.
activation: تابع فعالسازی که استفاده میشود. به طور پیشفرض ‘tanh’ است.
use_bias: آیا یک بایاس باید به خروجی اضافه شود یا خیر.
return_sequences: اگر True باشد، خروجی برای هر عنصر ورودی دنبالهای برگردانده میشود؛ اگر False باشد، فقط خروجی آخرین عنصر برگردانده میشود.
return_state: اگر True باشد، علاوه بر خروجی، حالتهای نهایی نیز برگردانده میشوند.
tf.keras.layers.LSTM و tf.keras.layers.GRU
این دو لایه پارامترهای مشابهی با SimpleRNN دارند، با این تفاوتها:
units, activation, use_bias, return_sequences, return_state: همانند توضیحات داده شده برای SimpleRNN.
dropout: نرخ حذف برای ورودیها، جهت جلوگیری از بیشبرازش.
recurrent_dropout: نرخ حذف برای وزنهای بازگشتی.
PyTorch
torch.nn.RNN
input_size: تعداد ویژگیهای ورودی در هر عنصر از دنباله.
hidden_size: تعداد ویژگیها در حالت پنهان.
num_layers: تعداد لایههای RNN تکرار شده.
nonlinearity: تابع فعالسازی که استفاده میشود (‘tanh’ یا ‘relu’).
bias: اگر False باشد، در مدل بایاس اضافه نمیشود.
batch_first: اگر True باشد، ورودیها و خروجیها به صورت (batch, seq, feature) خواهند بود.
dropout: نرخ حذف اضافه شده به خروجی هر لایه، به جز لایه آخر.
bidirectional: اگر True باشد، یک RNN دوجهته ایجاد میشود.
torch.nn.LSTM و torch.nn.GRU
این دو لایه پارامترهای مشابهی با RNN دارند، بدون پارامتر nonlinearity، چرا که LSTM و GRU ساختارهای خاص خود را دارند.
نکته مهم
انتخاب این پارامترها بر اساس مشکل مورد نظر، دادهها و تجربیات قبلی انجام میشود. معمولاً، تنظیم پارامترها (Hyperparameter Tuning) به صورت آزمون و خطا و با استفاده از روشهایی مانند جستجوی گرید (Grid Search) یا جستجوی تصادفی (Random Search) انجام میشود تا بهترین ترکیب پارامترها برای بهینهسازی عملکرد مدل یافت شود.
ادامه توضیح پارامترهای شبکه عصبی RNN در پایتون
بیایید برخی از جنبههای پیشرفتهتر و نکات مهم دیگری که هنگام کار با RNNها در پایتون باید در نظر گرفت را بررسی کنیم.
مقداردهی اولیه وزنها (Weight Initialization)
مقداردهی اولیه وزنها میتواند تأثیر قابل توجهی بر سرعت همگرایی و حتی کیفیت نهایی مدل آموزش داده شده داشته باشد. برخی از کتابخانهها مانند TensorFlow و PyTorch مقداردهی اولیه پیشفرض برای وزنها را فراهم میکنند، اما ممکن است بخواهید این مقادیر را بر اساس نیازهای خاص خود تنظیم کنید.
مدیریت حافظه (Memory Management)
RNNها، به ویژه مدلهای با لایههای متعدد یا دوجهته، میتوانند به سرعت منابع قابل توجهی از حافظه را مصرف کنند. استفاده از تکنیکهایی مانند حذف (dropout) یا تنکسازی (sparsity) میتواند به کاهش این مصرف کمک کند.
برش زمانی (Truncated Backpropagation Through Time)
برای جلوگیری از مسائل مربوط به گرادیانهای ناپایدار در RNNها، میتوان از تکنیکی به نام برش زمانی استفاده کرد. این روش شامل محدود کردن تعداد گامهای زمانی که گرادیانها در طول آنها محاسبه میشوند، است.
مدلهای توجه (Attention Models)
در کنار RNNهای سنتی، مدلهای مبتنی بر توجه (مانند Transformer) نیز برای پردازش دنبالهها محبوبیت زیادی پیدا کردهاند. این مدلها میتوانند به طور موثرتری وابستگیهای بلندمدت را در دادهها یاد بگیرند.
پیادهسازی و بهینهسازی
Stateful vs Stateless: RNNها میتوانند به صورت stateful یا stateless پیادهسازی شوند. در حالت stateful، حالت مخفی بین دستههای متوالی دادهها حفظ میشود، در حالی که در حالت stateless، حالت مخفی بین دستهها بازنشانی میشود.
Teacher Forcing: یک تکنیک آموزش که در آن خروجی صحیح در گام زمانی قبلی به عنوان ورودی بعدی به شبکه داده میشود. این روش میتواند به سرعت بخشیدن به فرآیند آموزش کمک کند.
Gradient Clipping: برای جلوگیری از مشکل انفجار گرادیان، میتوان مقادیر گرادیانها را در یک محدوده خاص محدود کرد.
نتیجهگیری
پارامترها و تکنیکهای معرفی شده تنها بخشی از مجموعهای گستردهتر هستند که هنگام کار با RNNها و سایر مدلهای یادگیری عمیق باید در نظر گرفت. انتخاب و تنظیم دقیق این پارامترها میتواند تأثیر چشمگیری بر عملکرد مدل نهایی داشته باشد.
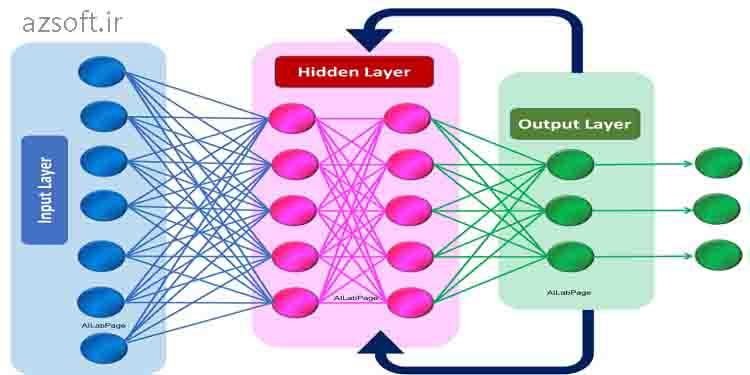
توضیح پارامترهای شبکه عصبی rnn در متلب
در متلب (MATLAB)، برای کار با شبکههای عصبی بازگشتی (RNN)، معمولاً از جعبه ابزار Deep Learning Toolbox استفاده میشود. این جعبه ابزار امکانات گستردهای برای ساخت، آموزش و ارزیابی شبکههای عصبی عمیق فراهم میکند. در ادامه، به توضیح پارامترهای کلیدی هنگام کار با RNNها در متلب میپردازیم:
1. ساخت شبکه RNN
برای ساخت یک شبکه RNN در متلب، ممکن است از لایههای مختلفی مانند sequenceInputLayer, lstmLayer, gruLayer, bilstmLayer و غیره استفاده کنید. هر یک از این لایهها پارامترهای خاص خود را دارند:
sequenceInputLayer: این لایه ورودی دنبالههای دادهای را تعریف میکند.
InputSize: اندازه ویژگیهای هر عنصر از دنباله.
lstmLayer / gruLayer / bilstmLayer: این لایهها نوعی از RNN هستند که برای کاهش مشکل محو شدن یا انفجار گرادیان طراحی شدهاند.
NumHiddenUnits: تعداد واحدهای پنهان در هر لایه.
OutputMode: تعیین میکند که آیا شبکه باید برای هر عنصر ورودی خروجی تولید کند (‘last’ برای فقط آخرین عنصر، ‘sequence’ برای تمام عناصر).
RecurrentWeightsInitializer, InputWeightsInitializer: مقداردهی اولیه برای وزنهای بازگشتی و وزنهای ورودی.
BiasInitializer: مقداردهی اولیه برای بایاسها.
2. آموزش شبکه
برای آموزش شبکه، از تابع trainNetwork استفاده میشود که نیاز به دادههای آموزشی و یک سری از پارامترهای آموزش دارد:
X: دادههای ورودی.
Y: برچسبها یا پاسخهای صحیح.
options: ایجاد شده توسط تابع trainingOptions که پارامترهای آموزش مانند نرخ یادگیری، تعداد epochها، الگوریتم بهینهسازی و غیره را تعیین میکند.
3. پارامترهای آموزش
تابع trainingOptions پارامترهای مختلفی برای تنظیم فرآیند آموزش فراهم میکند:
Solver: الگوریتم بهینهسازی مورد استفاده، مانند ‘adam’, ‘sgdm’.
MaxEpochs: حداکثر تعداد دورههای آموزشی.
MiniBatchSize: اندازه دستههای کوچک برای آموزش.
InitialLearnRate: نرخ یادگیری اولیه.
LearnRateSchedule: برنامهریزی تغییر نرخ یادگیری، مانند کاهش نرخ یادگیری بر اساس دوره یا عملکرد.
GradientThreshold: محدود کردن بزرگی گرادیان برای جلوگیری از انفجار گرادیان.
4. ارزیابی و پیشبینی
پس از آموزش شبکه، میتوانید از توابعی مانند predict برای انجام پیشبینیها استفاده کنید.
نکات مهم
انتخاب پارامترهای مناسب برای مدل RNN نیازمند آزمایش و تجربه است. ممکن است لازم باشد پارامترهای مختلفی را امتحان کنید تا بهترین عملکرد را برای مسئله خاص خود بیابید.
استفاده از GPU میتواند سرعت آموزش شبکههای عمیق را به طور قابل توجهی افزایش دهد. متلب امکان استفاده از GPU را برای آموزش و پیشبینی فراهم میکند، به شرطی که سختافزار مناسب وجود داشته باشد.
با توجه به این پارامترها و نکات، میتوانید شبکههای RNN خود را در متلب با اطمینان بیشتری ساخته، آموزش دهید و ارزیابی کنید.
استفاده از RNN در متلب برای پردازش دنبالهها
پس از بررسی پارامترهای اصلی و نحوه کار با شبکههای عصبی بازگشتی (RNN) در متلب، بیایید به چگونگی استفاده از این شبکهها برای پردازش دنبالهها و برخی نکات پیشرفته بیشتر بپردازیم.
مثال: پیشبینی سری زمانی با LSTM
فرض کنید میخواهیم یک سری زمانی را با استفاده از شبکه LSTM در متلب پیشبینی کنیم. اینجا یک چارچوب اساسی برای انجام این کار است:
آمادهسازی دادهها: ابتدا، دادههای سری زمانی خود را به فرمت مناسب برای آموزش شبکه تبدیل کنید. این شامل نرمالسازی دادهها و تقسیم آنها به دستههای کوچک (mini-batches) است.
ساخت مدل: سپس، یک شبکه با استفاده از لایههای sequenceInputLayer, lstmLayer, و fullyConnectedLayer برای پیشبینی ایجاد کنید. انتخاب تعداد واحدهای پنهان در lstmLayer و تعداد نورونها در fullyConnectedLayer بستگی به پیچیدگی مسئله دارد.
آموزش مدل: با استفاده از تابع trainNetwork و دادههای آموزشی آماده شده، مدل را آموزش دهید. انتخاب پارامترهای مناسب آموزش مانند نرخ یادگیری و تعداد epochها بسیار مهم است.
ارزیابی مدل: پس از آموزش، عملکرد مدل را روی دادههای تست ارزیابی کنید. این میتواند شامل محاسبه معیارهایی مانند خطای میانگین مربعات (MSE) باشد.
پیشبینی: با استفاده از مدل آموزش دیده، پیشبینیهایی را برای دادههای جدید انجام دهید.
نکات پیشرفته
تنظیم پارامترهای مدل: تنظیم دقیق پارامترها میتواند به بهبود عملکرد مدل کمک کند. این شامل تنظیم تعداد واحدهای پنهان در LSTM، نرخ یادگیری، اندازه دستهها و غیره است.
جلوگیری از بیشبرازش: استفاده از تکنیکهایی مانند Dropout یا Early Stopping میتواند به جلوگیری از بیشبرازش کمک کند. در متلب، میتوانید از پارامتر dropoutLayer برای افزودن لایههای حذف و از تنظیمات trainingOptions برای پیکربندی early stopping استفاده کنید.
استفاده از GPU: آموزش شبکههای عمیق میتواند زمانبر باشد. استفاده از GPU میتواند سرعت آموزش را به طور قابل توجهی افزایش دهد. مطمئن شوید که تنظیمات trainingOptions را برای استفاده از GPU پیکربندی کردهاید، اگر سختافزار مناسب در دسترس است.
با پیروی از این مراحل و نکات، میتوانید شبکههای RNN پیشرفتهای را در متلب برای حل مسائل مرتبط با دنبالهها و سریهای زمانی پیادهسازی و آموزش دهید.


پاسخ دادن