گروه تخصصی پردازش زبان طبیعی nlp azsoftir آماده انجام پروژه هایه پردازش زبان طبیعی nlp در زمان تعیین شده وبا بهترین کیفیت می باشد .پروژه هایه خود را می توانید از طریق ایمیل آدرس azsoftir@Gmail.com یا شماره 09367292276 یا از لینک زیر ثبت پروژه ارسال کنید.
پردازش زبان چیست ؟
معرفی پردازش زبان طبیعی
پردازش زبان طبیعی از سال 1950 مورد توجه قرار گرفت .اگر چه قبلا کارهایی بر رویه پردازش طبیعی انجام شده بود که می توان به مقاله منتشر شده با عنوان هوش محاسباتی وماشین کامپیوتری توسط آن تورینگ اشاره کرد .
کارهایی که در زمنیه پردازش متن قابل انجام هست ؟
انجام پروژه هایه دانشجویی nlp
انجام پروژهه هایه پردازش زبان طبیعی
انجام پروژه nlp در پایتون pythoon
انجام پروژه هایه هوش مصنوعی nlp
انجام پروژه هایه Natural Language Processing
پروژه nlp
پروژه پردازش زبان طبیعی
سفارش پروژه پردازش طبیعی nlp

پردازش ربان طبیعی nlp مخفف عبارته (Natural Language Processing)می باشد.برایه شناخت زبان محاوزه ای بینه سیستم کامپیوتری وانسان استفاده می شود.
اولین ترجمه متن توسط تاون در سال 1954 استفاده شد.در سال 1966 نیز کاری انجام شد که البته کاری از پیش نبرد در سال 1980 تحقیقات اندکی با موفقیت در زمینه ترجمه ماشینی انجام شد.
تا سال 1980 پردازش زبان طبیعی بیشتر بر اساسه قانونهایه دست نویس بود اما اوخر همین هوش مصنوعی تحولات زیادی را پردازش زبان طبیعی ایجاد کرد.برخی از الگوریتم هایه اولیه یادگیری ماشین مثله درخت تصمیم شبیه قواعد دست دستی ایجاد کردند .
پردازش زبان طبیعی
پردازش زبان طبیعی nlp
پردازش زبان طبیعی در واقع روشی برای درک زبان انسان توسط سیستم هایه کامپیوتری می باشد.
پردازش زبان طبیعی یا همان NLP معروف در واقع یک فناوری برای درک زبان انسان توسط کامپیوترهاست.
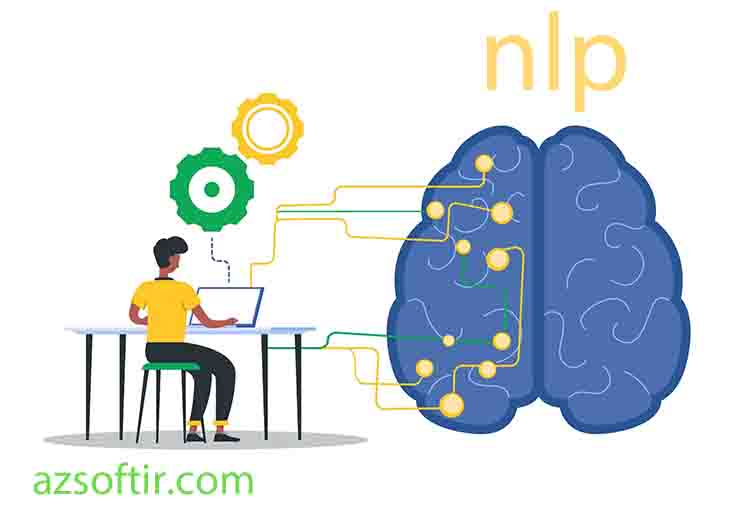
اما روشی که بتوان مثلا فایل صوتی یا متن کامپیوتری یا فایل متنی تصویر را به کامپیوتر بصورت هوشمند معرفی کرد وآن کامپیوتر آن را درک کرد بسیار با اهمیت می باشد در واقع در پردازش زبان متنی NLP هدف همین می باشد.
ارتباط پردازش زبان طبیعی NLP وهوش مصنوعی
پردازش زبان طبیعی یکی از زیر شاخه هایه هوش مصنوعی محسوب می شود ارتباط زبان بینه انسان وکامپیوتر می باشد.ارتباط بینه زبان انسان وکامپیوتر در چند گام انجام میشود .
نمونه از پردازش زبان طبیعی
در گام اول انسان با کامپیوتر صحبت می کند
در گام دوم کامپیوتر صدای انسان را ذخیره می کند
در گام سوم کامپیوتر این صدا به نوشته معادل تبدیل می کند .
همین متن را کامپیوتر بر اساسه متن تبدیل شده را تلفظ میکند .
بدین روش ارتباط بینه انسان وکامپیوتر برقرار میشود .
کاربرد nlp
کاربرد پردازش زبان طبیعی
پردازش زبان طبیعی NLP کاربرد زیادی دارد:
بطور مثال
ترجمه متن :شبیهی چیزی که در گوگل ترنسلیت استفاده میشود .
در برنامه هایه ویرایشکر در اصلاح گرامرونوشتار کلمات کاربرد دارد.
روشهایه پردازش در NLP
1-تحلیل گرامری
در این روش در کنار هم قرار دادن لغات می توان جملات را درست کرد. از این نظر می توان آنالیز گرامی اشاره کرد .
2-تحلیل معنایی
برایه فهم دقیق معنایه درست متن بکار می رود .این مورد سخت ترین کارهایه پردازش متن می باشد.
مراحل پیش پردازش انجام پروژه nlp
پیش پردازش در پروژههای NLP (پردازش زبان طبیعی) مجموعهای از فعالیتها و مراحل است که قبل از اعمال الگوریتمها و مدلهای یادگیری ماشین یر روی دادههای انجام میشود. این مراحل شامل تمیزکاری، توکنبندی، حذف توکنهای متنی غیرضروری، نرمالسازی و استخراج ویژگیها میشود. در زیر به صورتلاصه به مراحل پیش پردازش در پروژههای NLP اشاره میکنم:
تمیزکاری (Cleaning): در این مرحله، دادههای متنی از عناصر غیرضروری مانند علائم نگارشی، کاراکترهای خاص و اطلاعات تکراری پاکسازی میشوند.
توکنبندی (Tokenization): در این مرحله، جملات و متن به توکنهای کوچکتر تقسیم میشوند. توکنها میتواننداژگان، عبارات یا حروف باشند.
حذف توکنهای غیرضروری (Stopword Removal): توکنهایی که ارزش اطلاعاتی کمتری دارند و در فهرست توقف (Stopword) قرار دارند، حذف میشوند. این توکنها مانند “و”، “به”، “از” و غیره هستند.
نرمالسازی (Normalization): در این مرحله، توکنها به شکل استاندارد یا نرمال شدهرار میگیرند. برخی از روشهای نرمالسازی شامل لمگیری (Lemmatization) و استمگیری (Stemming)(ریشه یابی )است.
استخراج ویژگیها (Feature Extraction): در این مرحله، ویژگیهای معنایی و مفهومی ازتن استخراج میشوند. این ویژگیها میتوانند شامل بردارهایاژگانی (Word Vectors)، بردارهای توصیفی (Descriptor Vectors) و یا ویژگیهای دست ساز باشند.
این مراحل فقط یک نمونه از مراحل پیش پردازش در پروژههای NLP هستند بسته به نوع پروژه عملیات ها ،با هم تفاوت خواهد داشت .
روش های استخراج ویژگی انجام پروژه nlp
در پروژههای NLP (پردازش زبان طبیعی)، استخراج ویژگیها از متنها یک مرحله کلیدی است. در زیر، چند روش معمول برای استخراج ویژگیها در پروژههای NLP آوردهده است:
Bag-of-Words (BoW):
در این روش، هر سند را به عنوان یکجموعه از کلمات در نظر میگیریم و تعداد تکرار هر کلمه را به عنوان ویژگی مورد استفاده قرار میدهیم. این روش ساده است و معمولاً با استفاده از روشهایی مانند TF-IDF برای وزندهی به کلمات بهبود مییابد.
N-grams:
در این روش، به جای استفاده از کلمات به صورت تکی، دنبالههایی از کلمات (N-gram) را به عنوان ویژگیها استفاده میکنیم. این روش به ما امکان میدهد تا اطلاعات بیشتری را از ترتیب و ساختارلمات در متن استخراجنیم.
TF-IDF (Term Frequency-Inverse Document Frequency):
در این روش، هر کلمه را با استفاده ازو معیار TF و IDF وزندهی میکنیم. TF نشان میدهد که چقدر یک کلمه در یک سند تکرار شده است و IDF نشان میدهد که چقدر یک کلمه در کل مجموعه اسناد تکرار شده است. با ضرب این دو معیار، وزنر کلمه را محاسبه میکنیم و آن را به عنوان ویژگی استفاده میکنیم.
Word Embeddings در اینوش، کلمات را به فضایرداری تبدیل میکنیم. این فضای برداری معمولاً با استفاده از الگوریتمهایی مانند Word2Vec، GloVe یا FastText ایجاد میشود. در این فضا، هر کلمه را با یک بردارددی نمایش میدهیم و اینردارها را به عنوان ویژگیها استفادهیکنیم.
مدلهای زبانی پیشآموزش دیده از اخیراً، مدلهای زبانی پیشآموزش دیده مانند
BERT، GPT و Transformer درروژههای NLP بسیار موفق بودهاند. این مدلها قادرند ویژگیهای با کیفیت بالا را از متن استخراج کنند و معمولاً با استفاده از لایههای آخر مدل برای استخراج ویژگیها استفاده میشوند.
روش های استخراج ویژگی در پروژه های پردازش زبان طبیعی (NLP) به صورت زیر است:
استفاده از روش های مبتنی بر قوانین: در این روش، قوانین گرامری و زبانی برای تشخیص ویژگی ها استفاده می شود. این روش معمولاً برای تشخیص ویژگی های ساختاری مانند نحو و گرامر زبان استفاده می شود.
استفاده از روش های مبتنی بر ماشین: در این روش، الگوریتم های یادگیری ماشینی برای تشخیص ویژگی ها استفاده می شوند. این روش معمولاً برای تشخیص ویژگی های معنایی مانند دسته بندی متن، تحلیل احساسات و تشخیص موجودیت ها استفاده می شود.
استفاده از روش های مبتنی بر آمار: در این روش، آماره ها و ویژگی های آماری برای تشخیص ویژگی ها استفاده می شوند. مثلاً تعداد کلمات، تعداد تکرار کلمات و توزیع فرکانس کلمات می توانند ویژگی های مفیدی برای تحلیل متن باشند.
استفاده از روش های مبتنی بر ویژگی های موجود: در این روش، ویژگی های موجود در متن (مانند تعداد کلمات، طول جملات، تعداد حروف و …) برای تشخیص ویژگی ها استفاده می شوند. این روش معمولاً برای تشخیص ویژگی های ساختاری و آماری استفاده می شود.
استفاده از روش های مبتنی بر شبکه های عصبی: در این روش، شبکه های عصبی برای تشخیص ویژگی ها استفاده می شوند. این روش معمولاً برای تشخیص ویژگی های معنایی و ساختاری پیچیده استفاده می شود.
استفاده از روش های مبتنی بر ویژگی های مبتنی بر معنا: در این روش، ویژگی های مبتنی بر معنا مانند واژگان مشابه، روابط معنایی و مفهومی بین کلمات و مفاهیم استخراج می شوند. این روش معمولاً برای تحلیل معنایی و مفهومی متن استفاده می شود.
استفاده از روش های مبتنی بر تحلیل احساسات: در این روش، ویژگی های مرتبط با احساسات و نظرات مانند احساس مثبت یا منفی، قوت احساس و موضوعات مرتبط با احساس استخراج می شوند. این روش معمولاً در تحلیل نظرات و احساسات متن استفاده می شود.
استفاده از روش های مبتنی بر تحلیل موجودیت ها: در این روش، موجودیت های مختلف مانند افراد، مکان ها، شرکت ها و … استخراج می شوند. این روش معمولاً در تحلیل موجودیت ها و تشخیص معنایی متن استفاده می شود.
هر یک از این روش ها ممکن است با استفاده از الگوریتم ها و روش های مختلفی پیاده سازی شوند. علاوه بر این، می توان از ترکیب چندین روش با هم بهره برد تا بهترین نتیجه را در استخراج ویژگی ها در پروژه های NLP به دست آورد.
بعضی از الگوریتمها و روشهای معروف برای استخراج ویژگیها در پروژههای NLP عبارتند از:
استفاده از روشهای مبتنی بر رویکردهای مرتبط با متن: این روشها شامل استفاده از روشهای مبتنی بر کاوش اطلاعات، تحلیل انتشارات و پردازش زبان طبیعی است. این روشها برای استخراج ویژگیهای متنی مانند موضوعات، کلیدواژهها، خلاصهها و خصوصیات متن استفاده میشوند.
استفاده از روشهای مبتنی بر ویژگیهای زبانی: این روشها شامل استفاده از ویژگیهای زبانی مانند نحو، معنا، ساختار جملات و واژگان است. این روشها برای استخراج ویژگیهای زبانی مانند نشانگرهای زمانی، واژگان کلیدی و قواعد گرامری استفاده میشوند.
استفاده از روشهای مبتنی بر تحلیل شبکههای اجتماعی: این روشها برای استخراج ویژگیهای ارتباطی و اجتماعی مانند روابط بین افراد، تأثیرگذاری و شباهتها استفاده میشوند. این روشها معمولاً در تحلیل نظرات، تحلیل شبکههای اجتماعی و تحلیل تأثیرگذاری مورد استفاده قرار میگیرند.
استفاده از روشهای مبتنی بر تحلیل صوتی: این روشها برای استخراج ویژگیهای مرتبط با صوت مانند تشخیص سخنران، تشخیص احساسات از صدا و تشخیص گفتار استفاده میشوند.
روش های انتخاب ویژگی در انجام پروژه های nlp
در پروژه های پردازش زبان طبیعی (NLP)، انتخاب ویژگیها یک مرحله مهم است که میتواند تأثیر زیادی در عملکرد مدلها و دقت نتایج داشته باشد. در زیر، چند روش معمول برای انتخاب ویژگی در پروژه های NLP آورده شده است:
انتخاب ویژگی در انجام پروژه های nlp روشهای مبتنی بر تعداد تکرار (Frequency-based methods): در این روش، ویژگیهایی که بیشترین تکرار را در مجموعه دادهها دارند، انتخاب میشوند. به عنوان مثال، میتوانید برای هر کلمه در متن، تعداد تکرار آن کلمه را محاسبه کنید و کلماتی که بیشترین تکرار را دارند را به عنوان ویژگی انتخاب کنید.
انتخاب ویژگی در انجام پروژه های nlp روشهای مبتنی بر اطلاعات (Information-based methods): در این روش، از معیارهایی مانند اطلاعات متقابل (mutual information) و نسبت اطلاعات (information gain) برای انتخاب ویژگی استفاده میشود. این معیارها توانایی اندازهگیری اهمیت ویژگیها را در تعیین دستهبندیها دارند.
انتخاب ویژگی در انجام پروژه های nlp روشهای مبتنی بر مدل (Model-based methods): در این روش، از مدلهای یادگیری ماشین برای انتخاب ویژگی استفاده میشود. این مدلها میتوانند مدلهای مختلفی مانند رگرسیون لجستیک (logistic regression) و درخت تصمیم (decision tree) باشند. این مدلها معمولاً ویژگیهایی را که بیشترین ارتباط را با خروجی دارند، انتخاب میکنند.
انتخاب ویژگی در انجام پروژه های nlp روشهای مبتنی بر تحلیل عاملی (Factor analysis-based methods): در این روش، از تحلیل عاملی برای کاهش ابعاد ویژگیها استفاده میشود. با استفاده از تحلیل عاملی، ویژگیهای اصلی مجموعه داده را میتوان به عنوان ویژگیهای جدید استخراج کرد. این روش میتواند به کاهش پیچیدگی ویژگیها و افزایش قابلیت تفسیر مدلها کمک کند.
انتخاب ویژگی در انجام پروژه های nlp روشهای مبتنی بر تجزیهی موضوع (Topic modeling-based methods): در این روش، از روشهای تجزیهی موضوع مانند مدل لاتن دیریکلهی پنهان (Latent Dirichlet Allocation) استفاده میشود. با استفاده از این روش، میتوان تا حدی از موضوعات مختلف موجود در مجموعه داده آگاهی یافت و ویژگیهایی را انتخاب کرد که بیشترین ارتباط با موضوعات دارند.
انتخاب ویژگی در انجام پروژه های nlp روشهای مبتنی بر ویژگیهای متنوع (Diverse feature-based methods): در این روش، از ویژگیهای متنوعی استفاده میشود تا انواع مختلف اطلاعات را در نظر بگیرد. به عنوان مثال، میتوانید از ویژگیهایی مانند طول متن، تعداد کلمات، تعداد جملات و تعداد حروف مختلف استفاده کنید.
به طور کلی، در انتخاب ویژگی در پروژههای NLP، باید به توازن بین اهمیت ویژگیها و پیچیدگی مدلها توجه کرد. همچنین، میتوانید با ترکیب چندین روش مختلف، بهترین مجموعه ویژگیها را برای هر پروژه پیدا کنید.
روش های مدل سازی انجام پروژه های nlp
در پروژههای پردازش زبان طبیعی (NLP)، مدلسازی یکی از مراحل اساسی است که برای دستیابی به نتایج دقیق و قابل قبول از آن استفاده میشود. در زیر، چند روش معمول برای مدلسازی در پروژههای NLP آورده شده است:
انجام پروژه های nlp رگرسیون لجستیک (Logistic Regression): این روش یکی از روشهای پرکاربرد در پروژههای NLP است. در این روش، با استفاده از تابع لجستیک، احتمال تعلق یک نمونه به یک کلاس مشخص محاسبه میشود. این روش برای مسائل دستهبندی مانند تشخیص احساس (sentiment analysis)، تشخیص موضوع (topic detection) و تشخیص انواع متنوع دیگر استفاده میشود.
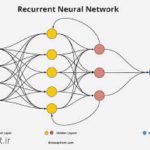
انجام پروژه های nlp شبکههای عصبی بازگشتی (Recurrent Neural Networks – RNN): این روش برای مدلسازی دنبالههای زمانی مانند تحلیل متن (text analysis) و ترجمه ماشینی (machine translation) استفاده میشود. با استفاده از ساختارهای بازگشتی در شبکههای عصبی، میتوان تعامل بین واحدهای زمانی مختلف را مدل کرد و اطلاعات مربوط به تاریخچه دنباله را در نظر گرفت.
انجام پروژه های nlp شبکههای عصبی پیچشی (Convolutional Neural Networks – CNN): این روش اغلب برای مسائل مربوط به تشخیص الگو در متون مانند تشخیص اسناد متنی (document classification) و تشخیص انواع متنوع دیگر استفاده میشود. با استفاده از لایههای پیچشی در شبکههای عصبی، میتوان ویژگیهای مهم و مرتبط با تشخیص الگو را استخراج کرد.
انجام پروژه های nlp ترنسفورمر (Transformer): این روش اخیراً بسیار محبوب شده است و در مسائل مانند ترجمه ماشینی و پرسش و
پاسخدهی مبتنی بر متن (text-based question answering) استفاده میشود. ترنسفورمر از لایههای توجه بصری (self-attention) برای مدلسازی ارتباطات متن استفاده میکند و قادر است به صورت همزمان اطلاعات متن را در نظر بگیرد.
انجام پروژه های nlp مدلهای مبتنی بر تجزیهی موضوع (Topic modeling-based models): در این روش، از مدلهایی مانند مدل لاتن دیریکلهی پنهان (Latent Dirichlet Allocation – LDA) استفاده میشود. این مدلها به منظور استخراج موضوعات مخفی و ویژگیهای مشترک در متون استفاده میشوند. با استفاده از این مدلها، میتوان متون را به موضوعات مختلف تجزیه کرده و از این موضوعات به عنوان ویژگیها در مدلهای دیگر استفاده کرد.
انجام پروژه های nlp مدلهای مبتنی بر ترجمه ماشینی (Machine Translation-based models): در این روش، از مدلهای ترجمه ماشینی مانند مدل مولتی-مولتی (Multi-Modal) استفاده میشود. با استفاده از این مدلها، میتوان متون را از زبان منبع به زبان هدف ترجمه کرده و از این ترجمهها به عنوان ویژگیها در مدلهای دیگر استفاده کرد.
انجام پروژه های nlp مدلهای مبتنی بر یادگیری تقویتی (Reinforcement Learning-based models): در این روش، از مدلهای یادگیری تقویتی مانند مدلهای Q-Learning استفاده میشود. با استفاده از این مدلها، میتوان مدلهایی را آموزش داد که بتوانند به صورت تعاملی و با دریافت بازخورد، تصمیمگیریهای بهتری در مورد مسائل NLP بگیرند.
همچنین، میتوانید با ترکیب چندین روش و تکنیک مختلف، بهترین مدلها را برای هر پروژه NLP پیدا کنید. به علاوه، میتوانید از روشهای ترکیبی مانند ترکیب مدلهای گوناگون، ترکیب ویژگیها و استفاده از ترکیب مدلهای مبتنی بر قواعد و مدلهای آماری نیز استفاده کنید.
در نهایت، هر روش مدلسازی دارای مزایا و محدودیتهای خود است و بسته به مسئله مورد نظر و مجموعه داده میتوانید روش مناسبی را انتخاب کنید. همچنین، همیشه میتوانید با آزمایش و ارزیابی روشهای مختلف، بهبود و بهینهسازی مدلهای خود را انجام دهید.
روش های ارزیایی مدل های پروژه های nlp
برای پروژه های پردازش زبان طبیعی (NLP)، می توان از روش های مختلف ارزیابی مدل ها استفاده کرد. در زیر چند روش ارزیابی معمول برای مدل های NLP آورده شده است:
دقت (Accuracy): این روش بر اساس تعداد صحیح و غلط پیش بینی های مدل است. این معیار در صورتی مفید است که تعداد داده های هر دسته یکسان باشد.
ماتریس درهم ریختگی (Confusion Matrix): این روش برای مسئله دسته بندی استفاده می شود و نشان می دهد که مدل چقدر صحیح و غلط کلاس ها را تشخیص داده است.
فراخوانی و دقت (Precision and Recall): این روش برای مسئله تشخیص داده ها استفاده می شود و نشان می دهد که مدل چقدر صحیح و غلط داده ها را تشخیص داده است. دقت معیاری برای صحت پیش بینی مثبت و منفی است و فراخوانی معیاری برای تشخیص درست داده های مثبت و منفی است.
ارزیابی F1 (F1 Score): این روش جمع بندی از دقت و فراخوانی است و برای مسئله تشخیص داده ها استفاده می شود. این معیار برای مقایسه مدل ها مفید است.
منحنی مشخصه عملکرد (ROC Curve): این روش برای مسئله تشخیص داده ها استفاده می شود و نشان می دهد که مدل چقدر توانایی تفکیک بین کلاس ها را دارد.
معیارهای BLEU و ROUGE: این معیارها به طور خاص برای ارزیابی کیفیت ترجمه و خلاصه سازی متن استفاده می شوند.
همچنین، تعدادی معیار دیگر نظیر معیارهای Perplexity، Word Error Rate (WER) و Character Error Rate (CER) نیز برای ارزیابی مدل های NLP مورد استفاده قرار می گیرند. انتخاب ر
وش مناسب برای ارزیابی مدل های NLP بستگی به نوع پروژه و مسئله مورد بررسی دارد. برای مثال، در مسئله تشخیص احساسات، معیارهای دقت، فراخوانی و F1 Score می توانند مناسب باشند. در حالی که برای مسئله ترجمه ماشینی، معیارهای BLEU و ROUGE می توانند مناسب باشند.
علاوه بر این، برای ارزیابی مدل های NLP می توان از روش های مقایسه ای مانند مدل های برتری، مدل های موجود در ادبیات و مدل های مقایسه شده با داده های بشری استفاده کرد. این روش ها معمولاً با استفاده از معیارهای کیفیت تولیدی مانند دقت ترجمه، صحت تشخیص داده ها و تفاوت معنایی بین خروجی مدل و متن مرجع انجام می شوند.
همچنین، برای ارزیابی مدل های NLP می توان از روش های تقییم مستندات مورد استفاده قرار گیرد. این روش ها شامل معیارهایی مانند خلاصه سازی مستندات، دسته بندی موضوعات و استخراج اطلاعات است.
در نهایت، برای ارزیابی مدل های NLP می توان از روش های تحلیل جریان متن استفاده کرد. این روش ها شامل تحلیل احساسی متن، تحلیل ارتباطات متنی و تحلیل رویدادها است.
لیست کاربردهای انجام پروژه های nlp
پروژه های nlp پردازش زبان طبیعی در سیستم های تشخیص گفتار: این پروژه ها می توانند بهبود قابلیت های تشخیص گفتار در سیستم هایی مانند تلفن های هوشمند، ربات های صحبت کننده و سیستم های ترجمه اتوماتیک برای زبان های مختلف را فراهم کنند.
پروژه های nlp تحلیل احساسات: با استفاده از پردازش زبان طبیعی، می توان احساسات کاربران را درباره متن ها، نظرات و پست های اجتماعی تحلیل کرد. این اطلاعات می تواند در زمینه هایی مانند تحلیل بازار، مدیریت ارتباط با مشتری و تحلیل رفتار مصرف کنندگان مفید باشد.
پروژه های nlp خلاصه سازی متن: پروژه های NLP می توانند متن های طولانی را به صورت خلاصه و مختصر تر تبدیل کنند. این کاربرد در حوزه هایی مانند مطالعه و تحلیل مقالات علمی، خبرخوان ها و سیستم های خلاصه سازی خبرها مورد استفاده قرار می گیرد.
پروژه های nlp ترجمه اتوماتیک: از طریق پردازش زبان طبیعی، می توان سیستم های ترجمه اتوماتیک را ارتقا داد و کیفیت ترجمه ها را بهبود بخشید.
تحلیل و تشخیص موضوع: با استفاده از الگوریتم های NLP، می توان موضوعات و کلیدواژه های مهم در متن ها را شناسایی کرد. این اطلاعات می تواند در تحلیل محتوای وب سایت ها، مدیریت دانش و تحلیل رفتار مصرف کنندگان مورد استفاده قرار گیرد.
پروژه های nlp تشخیص اسپم: با استفاده از الگوریتم های NLP، می توان اسپم ها را از پست ها و ایمیل ها تشخیص داد و جلوگیری از ورود آنها به صندوق
پروژه های nlp تحلیل ساختار جملات: با استفاده از پردازش زبان طبیعی، می توان ساختار جملات را تحلیل کرده و اجزای مختلف آنها را شناسایی کرد. این اطلاعات می تواند در حوزه هایی مانند گرامر چک، ترجمه زبانی و تحلیل متن های ادبی مورد استفاده قرار گیرد.
پروژه های nlp پرسش و پاسخ اتوماتیک: با استفاده از الگوریتم های NLP، می توان سیستم هایی را طراحی کرد که به سوالات کاربران پاسخ دهند. این کاربرد در سیستم های پشتیبانی مشتری، ربات های چت و سیستم های سوال و جواب مورد استفاده قرار می گیرد.
پروژه های nlp تحلیل رفتار کاربران: با استفاده از پردازش زبان طبیعی، می توان تحلیلی از رفتار و نیازهای کاربران در محیط های مختلف انجام داد. این اطلاعات می تواند در تحلیل رفتار مصرف کنندگان، تحلیل ارتباطات اجتماعی و بهبود تجربه کاربر مورد استفاده قرار بگیرد.
پروژه های nlp تولید متن خودکار: با استفاده از پردازش زبان طبیعی، می توان سیستم هایی طراحی کرد که به صورت خودکار متن ها و مقالات را تولید کنند. این کاربرد در حوزه هایی مانند سیستم های خبرنگاری، سیستم های تولید محتوا و سیستم های نگارش خودکار مورد استفاده قرار می گیرد.
پروژه های nlp تحلیل متن های قضایی: با استفاده از پردازش زبان طبیعی، می توان متون قضایی را تحلیل کرده و اطلاعات مهمی مانند نام اشخاص، تاریخ ها و جزئیات قضایی را استخراج کرد. این کاربرد در حوزه هایی مانند حقوق و قضاوت مورد استفاده
قرار می گیرد.
پروژه های nlp تحلیل اخبار و رسانه ها: با استفاده از پردازش زبان طبیعی، می توان اخبار و مقالات را تحلیل کرده و اطلاعات مهمی مانند موضوعات مهم، افراد مطرح و رویدادها را استخراج کرد. این کاربرد در حوزه هایی مانند رسانه ها، تحلیل رویدادها و تحلیل سیاسی مورد استفاده قرار می گیرد.
پروژه های nlp تشخیص ارتباطات اجتماعی: با استفاده از پردازش زبان طبیعی، می توان ارتباطات اجتماعی و شبکه های اجتماعی را تحلیل کرده و الگوها و روابط بین افراد را شناسایی کرد. این کاربرد در حوزه هایی مانند تحلیل شبکه های اجتماعی، مدیریت روابط مشتری و تحلیل رفتار مصرف کنندگان مورد استفاده قرار می گیرد.
پروژه های nlp تحلیل متن های علمی: با استفاده از پردازش زبان طبیعی، می توان مقالات علمی را تحلیل کرده و اطلاعات مهمی مانند موضوعات مورد بحث، روش های استفاده شده و نتایج به دست آمده را استخراج کرد. این کاربرد در حوزه هایی مانند پژوهش علمی، تحلیل مقالات و مدیریت دانش مورد استفاده قرار می گیرد.
تحلیل متن های شبکه های اجتماعی: با استفاده از پردازش زبان طبیعی، می توان متن های موجود در شبکه های اجتماعی را تحلیل کرده و اطلاعات مهمی مانند نظرات و تمایلات کاربران را استخراج کرد. این کاربرد در حوزه هایی مانند تحلیل رفتار مصرف کنندگان، تحلیل ارتباطات اجتماعی و تحلیل بازار مورد استفاده قرار می گیرد.


پاسخ دادن